System Design: Design a Geo-Spatial index for real-time location search

Introduction
We use real time location search services all the time in our real life — whether it’s a food ordering app or on-demand cab booking service, it’s everywhere nowadays. The intention of this article is to look into how to design the back end infrastructure for a Geo-spatial index in real life.
We will explore how several companies in relevant space have solved the problem, what are the pros & cons of different approaches & how you can approach the problem. Also we will see how to approach the problem in a System & Architecture Design Technical Interview perspective.
Some Real Life Use Cases
- Real time cab booking service like Uber, Lyft, Bolt.
- Real time hotel / restaurant search like Yelp.
- Target shoppers nearing a certain store for a marketing promotion.
- Hyper-local delivery system — dispatch delivery agents for restaurant order like Uber Eats.
Design Requirements
- Our service is used world wide.
- Given a location by a client or user, our service should figure out certain number of nearby locations.
- The infrastructure should be reliable.
- The system should response ≤ 200 milliseconds. So designing for latency is a big concern here.
- We need to support 50_000 read queries per second & 10_000 write queries per second.
- As users grow in our system, the system should scale linearly without adding much burden.
- For the sake of simplicity, let’s assume that a location is represented by
title,description,type,latitude&longitude. - The system is not multi-tenant.
- Clients are generally mobile clients, but web clients can also be there.
Quantitative Analysis
Let’s say we start with 200 million locations. The growth rate is 25% each year. Following are some estimations to start with.
Storage Estimation
As said, location is represented by title, type, description,lat, long .
Let’s assume some reasonable numbers for all those parameters: title = 100 bytes, type = 1 byte, description = 1000 bytes, lat = 8 bytes, long = 8 bytes
So a single location needs at least: (100 + 1 + 1000 + 16) bytes = ~1120 bytes = ~1200 bytes say.
For 200 million locations to start with, we need: 200 * 10⁶ * 1200 bytes = 240 Gigabytes.
With a growth rate of 25% each year, if we plan for say 5 years, we need to have support for:
1st Year: 240 Gigabytes
2nd Year: (240 + 240 * .25) = 300 Gigabytes
3rd Year: (300 + 300 * .25) = 375 Gigabytes
4th Year: (375 + 375 * .25) = ~470 Gigabytes
5th Year: (470 + 470 * .25) = ~600 GigabytesJust to store the location information in our data store, we need a bare minimum store of 600 Gigabytes, remember we may need more storage actually depending on what other metadata / auxiliary information we may need to store depending on our use cases or what metadata our data store internally stores in order to facilitate search or query operation on the data stored. So let’s extrapolate the the storage to a minimum of 1 Terabytes.
So how many machines we need to store 1 TB of data? -> Modern day, there are many database machine types (in AWS or Azure) which can offer storage from 16 TB to 64 TB depending on cost & use cases. So ideally 1 machine should be enough to support our use case. But remember, with a higher growth rate or with increasing popularity, we may need more storage or more machines. Nevertheless, we will design our infrastructure to support horizontal scaling.
Interview Tip: In real life, you can come up with detailed storage requirements once the expected growth rate is clear — typically the engineering & product teams work together to come up with the figures. But in an interview, you don’t need to calculate so much as it will consume significant time, you can calculate for the first year & extrapolate to some number. The intention is to show the interviewer that you take data driven decision with enough reasonable data size and growth in mind, don’t throw off unreasonable numbers, too much off-the-figures estimation is not okay.
Read Heavy vs Write Heavy System?
Our requirement already specifies that we have to support 50_000 read query & 10_000 write query per second. So it’s already established that our system is extremely read heavy & the Read:Write ratio is 5:1.
What if the requirement does not state / hint anything about Read:Write ratio, how would you determine that?
-> You have to first consider what kind of system you are designing. If you are designing something like Facebook News Feed or Twitter Timeline, that’s both read & write heavy system. If you are designing something like Google Search or Tweet search system, that’s extremely read heavy system, if you are designing a log shipping applications, that’s very write heavy application. Also consider how many daily active users (DAU) are there, how much content they are producing vs consuming on a daily basis — try to make an educated guess here, that figure will give you good idea about whether the system is read heavy or write heavy.
Interview Tip: For system design interview, try to have a fair idea about DAU of many different systems, prior to the interview, make a list of necessary information like DAU, daily tweets, daily how many photos / videos get uploaded to Facebook or Twitter, YouTube etc, or how many websites Google crawls or how many users does Yelp serve on a daily basis etc about variety of systems. Make a list of daily / monthly stats of read & writes for such applications.
In case you don’t have any idea about the scale of usage, try to throw a ball park figure by roughly thinking how much users or read/write the stated system may likely have & validate that with the interviewer. The interviewers usually help you with the scale in case your estimations are little off from what s/he thinks is correct. But don’t ask directly, take the first step to throw a rough ballpark suitable figure -> try to derive your own estimation from DAU and related parameters & then ask.
More importantly practice mock interviews or watch others’ mock interviews frequently to get comfortable with such figures & ideas.
Network Bandwidth Estimation
In order to do bandwidth & throughput calculation, we need to know how much data we transfer through the network. We will be able to do it properly only when we decide our API signatures. Let’s look the next section.
Network Protocol Choice
Since our requirement specifies that we need to support web & mobile clients, we need to choose a protocol which is developer friendly, easy to use & understand as 3rd party developers need to integrate with our infrastructure. There are couple of options like — SOAP, RESTful API over HTTP or RPC API.
SOAP: It’s quite old & complex to understand, pretty nested schema & typically XML is used to express the request & response. It’s not very developer friendly as well. We won’t choose SOAP.
RPC: It’s good for use cases suitable for communication in the same data centre & RPC requires client & server side stubs to be created which makes them tightly connected. Changing the client-server integration will be painful in case there is any need. So we won’t choose it.
RESTful with HTTP: This is something which nowadays has become the de-facto standard. It’s developer friendly, mostly developers use JSON schema to express request / response which is well understood in the community, easy to integrate & introduce new API version when required. For these reasons, we will go ahead with designing our API as RESTful API using HTTP.
API Signature
We need to decide a bare minimum API structure for request and response which can help us to expose our system to the outside world.
Get Locations API
Request:
Since we are designing a location based system, the bare minimum data that we need to take from the client is longitude & latitude . Also we can take radius as input in case we are supporting the flexibility for the client to specify a maximum radius to search for. Also we can take a max_count of matching locations that the client is interested in. So the GET HTTP API should look like below:
GET /v1/api/locations?lat=89.898&long=123.43&radius=50&max_count=30We are not concerned about authentication here, as we are assuming we have established authentication system already in place.
The parameters radius & max_count are optional parameters. We are also assuming our application service will have business logic to accurately determine what should be the maximum allowed radius or location count in case the client does or doesn’t specify any value for them in the GET locations API.
Response: The response looks like below
Notice that locations list in the response can contain minimum of max_count specified by the client or whatever is available in our system for the provided location.
Create Location API
Similarly we can have create location API as below:
The above POST API is a bulk API which can be used for creating a single location or multiple locations. Whether you need bulk or a single object API, it depends on what your client wants from your system. Do discuss with the clients or product manager.
Interview Tip: In an interview, you may need to clarify whether you need bulk API, if yes how much location objects you are supporting in the list should be explicitly stated as you can’t provide the flexibility of sending any number of objects since it will affect the throughput of the system or network efficiency.
The response code is 202 -> indicating that our system will asynchronously process the request just to make the API less latent.
Now since the API request & response schema is clear, let’s do the network bandwidth & throughput calculation.
Quantitative Analysis
Network Bandwidth Estimation
GET API bandwidth
For the GET locations API, let’s say we are supporting maximum 30 locations in the response list.
So, a single response object size is:
id(4 bytes considering int) + title (100 bytes) + description (1000 bytes) + lat (8 bytes) + long(8 bytes) = 1120 bytes.
For 30 locations, we have to send 1120 * 30 bytes = 33.6 Kilobytes = ~35 Kilobytes considering extra metadata like response headers & all.
So, a single GET request consumes 35 Kilobytes of bandwidth. If we support 50_000 GET queries, we have to support 35 * 50_000 Kilobytes per second = 1.75 Gigabytes = ~ 2 Gigabytes of data per second.
POST API bandwidth
We are supporting 10_000 write requests per second. Considering bulk write & the client is uploading maximum 30 locations per API call, we have to support the following throughput:
10000 * (30 * (title(100 bytes) + description(1000 bytes) + lat(8 bytes) + long(8 bytes))) = ~350 Megabytes per second.
This is fairly small but with growth, this figure can increase.
So combining read & write queries, we have to support (1.75 Gigabytes + 350 Megabytes) = ~2.1 Gigabytes data transfer per second.
This calculation indicates that we may need to distribute the load across our application servers to achieve such throughput as we are going to see more & more growth in the system.
Interview Tip: Doing so much of calculation in an interview may take long time to finish. So ask your interviewer whether you need to estimate such bandwidth. Typically storage and network bandwidth calculation should be enough for an interview — it does not need to be exact though, you may need to practice it for multiple use cases just to make sure you ate fast & comfortable enough with the calculations.
Database Schema
It’s very natural to think about the database schema when you are doing a high level design but think about the use cases first & ask yourself the following questions:
- What kind of location data are you storing? Is it static or dynamic?
-> If data is static like a restaurant location, it makes sense to put those location data into a data store since these locations are mostly static.
-> If the location data is very dynamic like cab’s location or delivery boy’s location & those locations constantly get pushed to your system, it does not make sense to store them in persistent data store unless you want to enable tracking for this or that purpose. - If you now realize that data store has to be used, what kind of store you are looking at?
-> Well, this is debatable topic, what to choose depends on your data model & data access pattern. There is a whole lot of debate between relational & non-relational store. But you can always start simple. It’s always easier to visualise data in tabular or relational format. Unless you explore, benchmark & compare different database technologies with your data according to their data model & find support for your use case in that technology, it’s hard to choose one.
At this point in time, let’s not choose any particular technology as of now but let’s go ahead with identifying what is the minimum data structure that we need to store in our data store.
Can’t we store dynamic data in data store as well? What will be the problem there?
-> We can store but insertion or update rate will be very high essentially making the system very costly in terms of disk / IO usage & rendering it useless for larger scale. We will see in later part of this article, how to deal with complete dynamic data.
How does the database schema look like?
-> As of now we can store the following schema which is pretty generic — depending on the database technology, the data type & size may change, nevertheless it will give a good picture to the design reviewers or interviewers about what you want to achieve. When required we might end up modifying it later.
Collection Name: Locations
--------------------------Fields:
-------
id - int (4+ bytes)
title - char (100 bytes)
type - char (1 byte)
description - char (1000 bytes)
lat - double (8 bytes)
long - double (8 bytes)
timestamp - int (4-8 bytes)
metadata - JSON (2000 bytes)
Interview Tip: It’s always a hot question in an interview whether to choose Relational or Non-Relational database. Many people blindly tell since read load is high, non-relational database will fit here well. This is not fully correct answer. No-SQL does not scale magically — there are some operational burden attached to it — it typically provides built-in support of sharding by application specified key which is a nice feature. When you choose a technology, you have to care about whether your data fits in the data model provided by the database system, how much community support that database system has, how the internal partitioning scheme in case of a No-SQL works for real world workload etc or whether it’s suitable for your use case. Based on just read-load or scale, it’s not logical to decide on a database. Remember in a very high scale system, only your database does not take the whole load, we will see several different components later in this article which together share the load & make up the system. Data store is just a part of it. Also many big companies use RDMS for a lot of their primary use cases. So irrespective of whether it’s a relational or non-relational system, we should see how the database technology fits in the landscape of our use case as well as in our existing company infrastructure. Also cost & operational excellence are another factors which are very very important to consider.
Anyway, in an interview settings, you can always start with RDBMS since every one understands it & say that based on the above factor we will choose the proper technology later whatever fits our bill.
High Level Design (HLD)
Since we have a fair idea now about our use cases, expectations & estimations, we can now move ahead to draw the high level design.
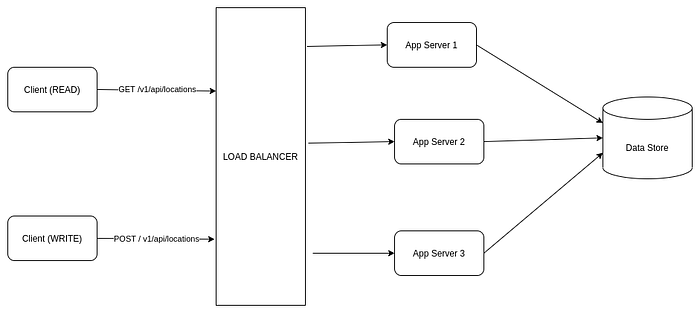
Figure 1 depicts the very basic HLD for our system. We have application servers placed behind a load balancer which accept traffic. Those app servers are deployed with our API definitions. Our API implementation connects to the database, fetches the result, forms the response & returns back to the client.
Ask yourself some questions here
1. Why do we need a load balancer here?
-> Since we have to serve 50_000 read queries per second, considering in the worst case all the traffic come from the same region, it will be difficult for a single server to manage that load. So we need stateless application servers which can share the load among themselves. Hence the load balancer comes into action.
2. What kind of load balancer is this? Hardware / Software?
-> Well that depends on our existing infra & cost optimization techniques. Software load balancers are less costlier than hardware one. Hardware load balancer may have special hardware requirements but more efficient & advanced than the software one. But in case we don’t have any standard or choices made yet, it’s perfectly fine to choose a Software Load Balancer something like HAProxy, in case you are creating services on AWS, you can get HAProxy load balancer provisioned form AWS itself. We don’t need any sophisticated load balancer like Layer 7 Application load balancer, we can simply use Layer 4 or Network load balancer.
3. What are we inserting in the database?
-> We saw in our API definition that we are accepting a list of location objects in JSON format. Our database schema is also pretty much consistent with the API. So we can simply store those location data in our data store -> we may need some validation, conversion or business logic implementation on that data before saving it to data store.
4. What are we querying in the database? How is the query performed?
-> This is the most interesting & tricky question to handle till now. Since we are simply using a data store, what query you perform it completely depends on the store used. If the data store supports native Geo-Location query, you might write that query to search for nearby locations in the application logic. However, not all data store supports location queries. Traditional RDMS systems like MySQL does not support native location query.
Nevertheless, since we are supporting a minimum 50_000 read queries per second that too with a constraint of ≤ 200 ms latency, it’s not practically possible to do the search all the time on the data store as we might hit network or disk IO bottlenecks.
Also it’s better if we design the system in such a way that irrespective of whatever data store we use, we are able to manage location queries seamlessly.
Now our problem statement becomes:
How to make the locations searchable since our data store might not natively supports it or even if it supports, we can’t put so much of load with growing scale?
-> Let’s talk about different approaches that we can think of to make the location search easier.
Approach 1: Cache locations & search in-memory
Our initial data size is around 240 Gigabytes & it can grow up to 600 Gigabytes or more in near future. Since we need to support massive read queries, can we do aggressive caching? If yes, how?
Our intention is to query the cache as much as possible & give less load to our database. To start with, can we accommodate all 240 Gigabytes of data in memory in cache machines?
-> Yes we can do that, but depending on the cost, we may need to have multiple machines. It’s possible to get a single machine with around 250+ Gigabytes of memory, but that might not be cost efficient. So we can have 2 cache machines each with 120+ GB memory & we can distribute our data to both of them.
What will you store in the cache?
-> In this approach, for any location query, we are finding distance between the client provided (lat, long) & all locations stored across all cache machines. After finding out all the result, we rank the locations based on ascending distance order & client provided criteria if any. This is basically a brute force search & we do it completely in memory, so it’s faster than doing the whole operation in database provided our database does not support location queries.
It does not matter in what format we store the locations, we may store the location id as key & the location object as value or if the cache supports list of objects, we can store list of locations against any key & search across the list of locations.
How will the cache get loaded?
-> We can have a scheduled job which will run every few minutes and load the locations since the last id or timestamp. This is not a real time process, so we can have our write path also write / update the location information when the POST location API gets called. In the following architecture the write path has 2 steps: Step 1: Write to the database, Step 2: Write to the cache. Now we can run this write sequentially since the database is our source of truth for static data, we need to make sure to write the data to our database first, then write to the cache cluster.
In the following architecture, the cache loader is a background process which acts as a reconciliation process — in case the step 2 in our write path fails, our cache loader will write the data since it finds the data is missing. In case the data is already present there, depending on the timestamp of the in-memory object, the loader can decide whether to update the data or skip it — if the database has more updated data / higher timestamp, update the data in cache. Also cache loader reads the data from a “Follower machine” — it’s just a way to scale the database — all write happen on the “Leader” & read happens on the “Follower” machines. There is a trade off here — the follower may log few milliseconds to seconds than the “Leader” since most of the real life use cases, we enable asynchronous replication instead of synchronous replication since synchronous is slower.
What is the strategy to partition the cache machines?
-> There are many strategies to partition the cache machines, but for now, let’s keep the system simpler & keep on filling a cache machine till the time it gets completely filled or filled up to a threshold. Once a machine gets filled up, we switch to the next machine.
Don’t you think in this strategy, cache load across machines will be imbalanced?
-> It depends, for systems like hotel / restaurant search, this system might work fine as we have very specific number of restaurants / hotels & there will be no sudden growth or spike in number of hotels / restaurants over night. So we have very relatively static amount of data & we already know how many cache machines are enough to contain this data.
With our cache loader background process & cache loading at the write path, all of our cache machine will eventually get filled, so for such a constant-growth data, we will anyway end up hitting both the machines sooner or later to fetch all location information while calculating distance. So such cache filling strategy should work fine in the given situation.
How to optimize cache partitioning for dynamic data?
-> We will see in later section.
How are you going to query the cache cluster?
-> We can use parallel threads to query the cache machines, process their data independently, combine them & create the response. So it’s like Divide & Conquer strategy.

Cool, can we do better than this system? We are querying all the cache machines for all the location queries. This is expensive. Can we do better?
-> Let’s move on to the next sections to know how to partition the cache in a better way.
Approach 2: Create partitions in memory & search partition wise
How can we do better than the previous approach?
Certainly, the bottleneck is querying all cache nodes for all read operations. We need to implement some sort of sharding / partitioning strategy to lessen the location search space.
How to implement a partition then?
Well, there is no standard partitioning that can be implemented for different use cases, it depends on what kind of application we are talking about & how the data access pattern looks like.
Let’s consider a hyper-local food delivery application. We need to assign delivery agents efficiently to customers so that orders can be dispatched in short time. There can be different kind of parameters which will determine whether a delivery agent can be assigned to an order e.g; how far the agent is from the restaurant & customer location, is he in transit & can take another order on his way and many others. But before applying all these filters, we need to fetch a limited number of delivery agents. Now most of the delivery agents will be bound to a city if not a specific locality. A delivery agent from Bangalore won’t usually deliver any order to a customer residing at Hyderabad. Also there will be finite number of agents in a city and possibly that number can hardly touch a maximum of few thousands only. And searching through these few thousands locations for a batch of orders ( orders from a locality or city can be batched & dispatched together for better system performance ) can be a good idea. So, with this theory, we can use city name as the partition key for a hyper local system.
How do you figure out the city name from the current location of a device?
-> Google Maps provides reverse Geo-Coding API to identify current city & related location information. The API can be integrated both in Android & iOS Apps.
Since the current location of delivery agents are dynamic mostly, we can have their mobile devices ping our server continuously with their latest location. The ping can happen say every 10 seconds. Also the current location that our server receives from the agent’s device expires in 10 seconds so that we don’t end up storing stale data since the location is dynamic. The following architecture depicts the new architecture:

We have made some changes in the previous architecture described in the Figure 1 & came up with the above new architecture.
We have introduced a location data sharding scheme based on city name (It could be city id as well in case there is a risk of city name collision). We divide location data into several logical shard. A server or physical machine can contain many logical shards. A logical shard contains all locations data belonging to a particular city only. In this allocation strategy, it might happen that a big city contains lots of locations whereas a smaller city contains less number of locations. In order to manage these shards & balance the load evenly across all possible cache servers, we are using a central metadata registry. The metadata registry contains mapping from city name to logical shard id, logical shard id to in-memory index server id mapping ( using service discovery mechanism, we can get the IP address of a server using the server id, the discussion is out of scope of this article ), something like below:
City to shard mapping:
----------------------city shard_id
------------------------
Bangalore 101
Hyderabad 103
Mumbai 109
New York 908
San Francisco 834Shard to Physical server mapping
--------------------------------shard_id index_server
----------------------------
101 index-1
103 index-2
109 index-1
908 index-3
834 index-2A shard (say index-1) content (location object) looks like below:"San Francisco": [
{
"agent_id": 7897894,
"lat": 89.678,
"long": 67.894
},
{
"agent_id": 437833,
"lat": 88.908,
"long": 67.109
},
...
]
Both the read & write request first talk to the metadata registry, using the IP address of the request’s origin, we determine in which city the delivery agent exactly is or from where the customer request came. Using the resolved city, shard id is identified, then using shard id, index server is identified. Finally the request is directed towards that particular index server. So we don’t need to query all the cache / index server any more. Note that, in this architecture, neither read nor write requests talk to the data store directly, this reduces the API latency even further.
Also in the above architecture, we are putting the data to a queue from which a consumer picks up those location data & updates the database with proper metadata like timestamp or order id etc. This is done only for tracking the history & tracing the delivery agent’s journey in case it’s required, it’s a secondary part to our discussion though.
Managing static partition in a central registry is a simpler way of managing partitions. In case we see one of the cache server is getting hot, we can move some of the logical shards from that machine to other machine or completely allocate a new machine itself. Also since it’s not automated & human intervention is required to manipulate or move partitions, usually chances of operational mistake is very less. Although there is a trade off here — with increasing growth or insane growth, when there are thousands of physical machines, managing static partition can become a pain, hence automated partitioning scheme should be explored & tools to be developed when those use cases arrive.
What are some trade-offs of choosing city as partition key?
-> It’s quite possible that one of our delivery agents is currently located near the boarder of two cities — say he is at city A, an order comes from a neighbour city B & the agent’s distance from the customer at city B is quite less, but unfortunately we can’t dispatch the agent as he is not in city B. So at times, city based partitioning may not be optimal for all use cases. Also with growing demand from a city for a particular occasion like Christmas or New Year, a city based shard can become very hot. This strategy might work for hyper local systems but not for a system like Uber due to its very high scale.
Uber employs similar partitioning strategy but it’s not only on city/region — it’s region + product type (pool, XL or Go whatever). Uber has geographically distributed products across countries. So partitioning by a combination of product type & city works fine for them. To search for available Uber pool cabs in a region, you just go to the pool bucket for that region & retrieve all the cabs currently available there & likewise for all other use cases.
You can find out more about their strategy in the following video:
What happens if one of the partition crashes? How do you recover data?
-> Since the location data is very dynamic & hardly stays for few seconds in our system ( since expiry time is less ), even if a partition crashes & then come back or we perform manual fail over, the data will automatically build up again as it’s continuously getting streamed from the client devices to our system.
Is there any other way that can be explored to partition millions to billions of locations?
Approach 3: Partition based on Geo-Hash & query matching hash
We have seen that if we have a very high scale like millions of queries per second ( for services like Uber, Lyft ), only region / city based partitioning can not save us. We need to find a strategy where we can minimize the search area even more or have a flexibility to increase or decrease the search area as per our need may be based on radius.
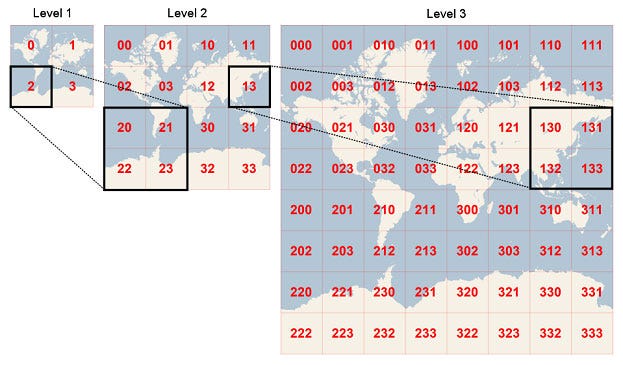
There is something called Geo-Hash, it’s an encoding mechanism for a given location ( lat, long pair ). The core concept is to imagine the earth as a flattened surface & keep on dividing the surface into multiple grids (squares or rectangles, depends on implementation). In the following figure, we first divide the flattened earth surface into 4 grids represented by 0, 1, 2 & 3. Each grid now represents 4 different regions of a large size something like 100_000 KM x 100_000 KM ( this figure is just for understanding purpose, may not be accurate ). This is just too big to search for matching locations. So we need to divide it further — now we will divide each of those 4 grids into 4 parts — so the grid 0 is now has 4 grids inside — 00, 01, 02, 03; the figure shows grid 2 is divided into 4 parts — 20, 21, 22, 23. Now say these smaller grids each represents an ares of size 20_000 KM x 20_000 KM. This is still too big. So we keep on dividing each of these squares into further 4 parts & the process recursively continues till we reach a point where each region / grid can be represented as something like 50 KM x 50 KM area or some area which is suitable for our optimal searching.
So conceptually, the more grids we add, the region area keeps on getting smaller — the precision of the area becomes very high & the length of the string representing the ares increases e.g; string "02" represents an ares of 20_000 KM x 20_000 KM, string "021201" may represent an area of 50 KM x 50 KM. Please note: these figures mentioned are not mathematically accurate, these are just for building our understanding about the core concepts of Geo-Hash. In short:
High precision Geo-Hashes have a long string length and represent cells that cover only a small area.
Low precision Geo-Hashes have a short string length and represent cells that each cover a large area.
So does all the Geo-Hash library represent the flattened earth as 4 grids initially?
-> This is not necessary. Many of the Geo-Hash library takes a base of 32 alphanumeric characters & keeps on dividing the surface into 32 rectangles. You can implement your own Geo-Hash library with any base per say. But the core concept remains same. I will write a separate article on the internals of Geo-Hash in future. In real life, we may need to compare existing Geo-hash libraries & see how good they are in terms of performance, APIs exposed & community support. In case they don’t fit our use case, we may need to write our own but chances are less. One good Geo-Hash library is Mapzen, take a look. Also remember that, in real life, cell / region dimensions may vary depending on longitude & latitude. It’s not all same area square or rectangles everywhere, nevertheless, the functionality remains same.
So how can we use Geo-Hash in our use case?
-> We need to first decide on a length of Geo-Hash which gives us a suitable area something like 30 to 50 square KM to search for. Typically, depending on the the Geo-Hash implementation, that length may be 4 to 6 — basically choose a length which can represent a reasonable search area & won’t result into hot shards. Let’s say we decide on length L. We will use this L length prefix as our shard key & distribute the current object locations to those shards for better load distribution.
Why does Geo-Hash concept work?
-> As we saw Geo-Hash of certain length represents an area of some finite square Kilometres. In real world, only finite number of cars or delivery agents or finite objects will fit in that area. So we can develop some estimations to figure out how much objects can be there in the worst case & calculate our index machine size accordingly that can reduce hot shard possibility. Since we have finite area with finite number of objects, we won’t have very hot shard anyway logically.
Interview Tip: Build an understanding on how Geo-Hash works so that you are comfortable talking about it or at least give a short overview to the interviewer as he might not know about this concept. It’s highly unlikely that an interviewer asks you about the internal mathematics of Geo-Hash, still, if possible try to understand the implementation of any Geo-Hash library, I have put one link in the references section.

Let’s see how does this architecture work step by step:
Write Path
- Our application receives constant ping containing current location details from objects like — delivery agents or drivers etc.
- Using the Geo-Hash library, the app server figures out the Geo-Hash of the location.
- The Geo-Hash is trimmed down to length
Lwhatever we decide. - The app server now talks to the central metadata server to decide where to put the location. The metadata server may return index server details immediately if any shard already exists for the Geo-Hash prefix or it may create an entry for a logical shard & map it to any suitable index server & returns the result.
- In parallel, the app server writes the data to the async queue to update the location in the database.
Read Path
- Our application server receives a (lat, long) pair whose nearest locations we need to find.
- The Geo-Hash is determined from the location, it’s trimmed down to length
L. - We find out the neighbouring Geo-Hash for the prefix. Typically all 8-neighbours. When you query for neighbours of a Geo-Hash, depending on implementation, you may get 8 sample points each belonging to the different 8-neighbours. Why do we need to figure out neighbours? It may happen that the location that we received in the API request resides near a border or an edge of the region represented by the Geo-Hash. Some points might be there which exist in the neighbouring regions but are very close to our point, also the prefix of the neighbour regions may not at all match with the prefix of our point. So, we need to find Geo-Hash prefix of all 8-neighbours as well to find out all nearby points properly.
- Now we have total
9prefixes of lengthL. One for the region where our point belongs to, another8for neighbours. We can fire9parallel queries to retrieve all the points belonging to all these regions. This will make our system more efficient and less latent. - Once we have received all the data, our application server can rank them based on distance from our point & return appropriate response.
Do we need to make any change to our low level design to support this technique?
-> We need to add Geo-Hash prefix to our database just in case in future we need to shard the db layer, we can do the same using hash prefix of length L as the shard key. Our new schema looks like below:
Collection Name: Locations
--------------------------Fields:
-------
id - int (4+ bytes)
title - char (100 bytes)
type - char (1 byte)
description - char (1000 bytes)
lat - double (8 bytes)
long - double (8 bytes)
geo_hash - char(10 bytes)
geo_hash_prefix - char(6 bytes)
timestamp - int (4-8 bytes)
metadata - JSON (2000 bytes)City to shard mapping:
----------------------geo_hash_prefix (length = L) shard_id
------------------------------------------
a89b3 101
ab56e 103
fy78a 109
c78ab 908
a78cd 834Shard to Physical server mapping
--------------------------------shard_id index_server
----------------------------
101 index-1
103 index-2
109 index-1
908 index-3
834 index-2
How can we implement such index in our system?
-> We need three basic things to implement such an index:
- Current location of an object (drivers in case of Uber, delivery agent’s location in case of a food delivery app).
- Mapping from a Geo-Hash prefix to the objects
- Proper expiry of the dynamic location data since in this use case, we are dealing with dynamic objects.
We can use Redis to model all the above requirements:
- We can represent the current location of an object as a normal key value pair where key is the object id & value is the location information. When we get a location pinged from a device, we identify the Geo-Hash of that location, take hash prefix of length
L, find out the shard & index machine where it lies from the central metadata registry & add or update the location information in that machine. The location keeps getting updated every10or30seconds whatever we decide. As you remember, these locations will keep on getting updated always. We can set the expiry to few minutes for this kind of key & with every update, we can increase the expiry time.
"7619": {"lat": "89.93", "long": 52.134, "metadata": {...}}2. For requirements 2 & 3 above, we can implement Redis sorted set (priority queue). The key of the sorted set will be the Geo-Hash prefix of length L. The member is objects’s id which are currently sharing the Geo-Hash prefix (basically they are withing the region represented by the Geo-Hash). And the score is current timestamp, we use the score to delete older data.
This is how we set Redis sorted set for a given object location belonging to a Geo-Hash prefix:ZADD key member score
ZADD geo_hash_prefix object_id current_timestampExample:
ZADD 6e10h 7619 1603013034
ZADD 6e10h 2781 1603013050
ZADD a72b8 9082 1603013089Let's say our expiry time is 30 seconds, so just before retrieving current objects for a request belonging to a Geo-Hash prefix, we can delete all data older than current timestamp - 30 seconds, this way, expiration will happen gradually over time:ZREMRANGEBYSCORE geo_hash_prefix -INF current_timestamp - 30 seconds-INF = Redis understands it as the lowest value
Any company implemented this strategy in real life?
-> Lyft implemented this strategy. For more details, watch the video below.
Is there any other way to create Geo-Spatial Index?
-> Google has an alternative solution to Geo Hashing called S2 library, it has a very poor documentation though. I will keep it as a separate topic for another blog post someday.
Any popular product using Geo-Hash?
-> MongoDB & Lucene use Geo-Hash for Geo-spatial indexing.
Finally, how to reduce the latency even further as our requirements says the system needs to be very responsive?
-> We can have replica of index servers across countries in case our data is static. For dynamic data like cab location, these are very region specific. So we can have geographically distributed index servers which are indexed only with data from the concerned region or country. Example: If we get data from China, only index servers from China will index that data. For fault tolerance purpose, we can have replica of index servers across country or different regions in a country. We can use DNS level load balancing to redirect the users from different country to the nearest available server.
We discussed several different real life approach to create a Geo-Location index. There is no single technique which can solve all problems. Depending on the scale of the system, users expectation on the system, we can choose different techniques which fits our bill.
There are many articles which use Quad-Tree to solve the same problem, however I am not sure how many companies in real life use those solutions or how scalable those solutions are practically. There are R-Tree or Uber’s hexagonal hierarchical spatial index based solutions available which I might write about in future articles.
Stay Tuned! I hope you have learned some practical techniques to create a Geo-Spatial index.
Please comment & let me know if you see any improvement to be done in this article or you have idea of any topic which you might want to hear from me.
