MySQL Key Value Store — A schema less approach

Almost all of us every day use some relational database in our job or different projects. In typical applications ( backend apps / mobile apps ), people are fine enough to create database models ( whether good or bad that’s a different topic ), write some sort of controller, views, services etc to create full fledged features. In relational paradigm, people take some use case, then they primarily think about models / db table schema, create more models, do a lot of joining in order to fetch data from normalised tables etc.
RDBMS are first choice of people because of the following reasons:
- Good ACID support.
- Easy SQL queries to access the data.
- Operational confidence in case something goes wrong.
- Reliability, maturity, community support & high performance on individual storage node.
- Support for secondary index.
But as business scales, typically consumer facing business, which grow say by X ( > 10 ) % month on month, the same RDBMS instance becomes a bottleneck because of the following reasons:
- Too Many Index — in order to make db operations faster, people create suitable index ( singular or composite index ) on different columns. So every time we update something, db has to update the index, maintain it. If there are millions of rows in a table and say you add a new column in a table, the operation may take several countable minutes to perform that operation as it takes a lock on the whole table in order to guarantee consistency. When we delete some column, it’s typical that the corresponding index stays & hogs up memory. So maintaining index becomes a real operational challenge.
- Sharding / Partitioning data: RDBMS systems struggle to scale with millions of data. No built in sharding mechanism. Developers create sharding mechanism which might or might not serve at scale well without solid failover mechanism or clustering per shard.
- Deadlock: Chances of deadlock even when tens of transactions are waiting or locked for resources.
- Table Joining: Lots of joining may create a lot of temp tables thus hogging up memory, disk, slowing up the query execution, timing out connections. Although, breaking a big query into multiple small queries can help here.
- Write Speed: RDBMS provide consistent write, they don’t write on the disk sequentially, even their B-Tree backed index is also random read/write data structure. So write speed at scale suffers.
- No Queue Support: Not all use cases require relational queries, some require FIFO ordering. Consider, your new feed on Facebook, if you want to store the feeds in a mysql table ( just a naive example ), you can do that ordering by timestamp, but internally, you are actually using the B-Tree based index which takes O(logN) time ( considering balanced tree) to operate on a data. This just does not scale well for simple FIFO dominated operations.
- No TTL support: RDBMS does not support out of the box TTL. So in such use cases where business does not need to store data forever, extra worker / cron jobs are to be written which will archive & delete the row, it adds up to the extra pressure when the traffic is in millions.
For all of the above reasons, depending on the use case, people use different NoSQL solutions like MongoDB, Cassandra, Amazon Dynamo DB etc. But those solutions have their own problems after all in technology every design decision is a result of some trade off. No matter whatever technology you use for your use case, things will break this way or that.
But it’s possible to create a key value store based on RDBMS solutions, the history of RDBMS usage & its advantages can intrigue developers to create such solution, moreover over the top you can implement your own custom features. MySQL engineers of Facebook, Google, Alibaba, Twitter, LinkedIn etc have taken an initiative called — WebScaleSQL in order to solve different challenges they face at extreme scale, it proves how much popular & adaptable mysql is for a global scale product. Some early days social media platform like FriendFeed ( acquired by Facebook in 2009 ), Uber, Twitter, Pinterest still rely on MySQL storage for hosting their mission critical data like trips, tweets etc at extremely high scale.
As mentioned, Uber built their schema less datastore based on MySQL to store millions of trips data. We will discuss in the similar line & see how some schema less solution can be built around MySQL.
The main motivation to build schema less system is to support schema less objects without cluttered index based on the reliability of MySQL. Companies dare to build such a system usually when they don’t have enough operational trust on the existing systems which are not battle tested at their scale as companies probably host the most import data on such a system & expose the system as a shared service company wide across thousands of services.
Let’s say we are building a ‘trip‘ database for our cab aggregator service. We have many parameters of a trip like — start_time, end_time, city, driver_id, customer_id, distance, passenger_id, vehicle_id, payment_object_id etc. Apart from that any aggregator service has to handle payments, after trip experience, rating etc. Typically if we build the initial version of such a system, in a relational database, we will probably make a trip model with the above mentioned parameters, we would have index on city, driver_id, start_time, passenger_id etc in order to speed up different queries to find data on trips, trips by a particular driver in a certain city, trips in a city, trips per day, trips by a passenger, payment history etc. But as days pass by, we would face the same problems as described in the top.
The idea of building a schema less datastore is to make the data format truly schema less, no schema validation on the data at all. We will not model trips as a database table, rather we will create json of trips data, save the trip data ideally in append only fashion in our database so that we don’t loose the previous state of the data as well as minimise the updates in order to get better database performance, version them with some incremental identifier. The same thing happens for payments data & any other domain also. So the basic building block for such a system are — a particular column to store json data, a column to hold attributes names of json data because json data is actually nothing but a serialised representation of actual domain data containing attributes with corresponding value, a column to store the version no or reference key, and an id preferably uuid to uniquely identify that domain ( say trip in our example ).
Following is a conceptual illustration:
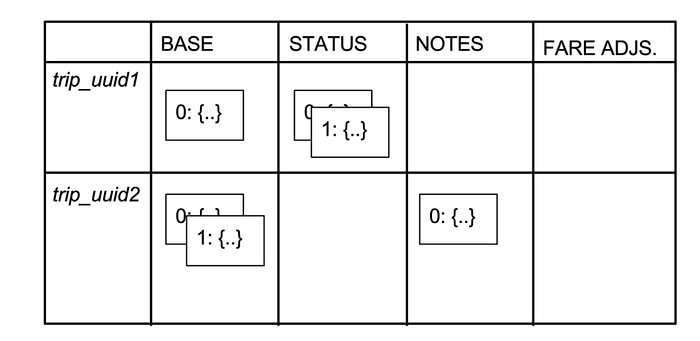
Here you can see different squares inside the ‘STATUS’ column of the for trip_uuid1, another 2 squares in ‘BASE’ column for trip_uuid2. These squares are called cells, they are nothing but conceptual representation of different states of the related data along with a version / reference number. This kind of schema essentially does grouping of same sort of data together in the same column, thus when you query the data with certain constraints, you get data with almost same schema, thus making manipulation of the data in the application layer easier. So the data model can be imagined with such a structure & if required you can also save certain denormalised data to help your query.
The Uber data model of schema less system is following:

Here added_id is the primary key, it makes MySQL write the cells linearly on disk.
row_key is nothing but the entity id say trip_uuid in trip database.
column_name hold the attribute / key of json data.
ref_key is the version identifier for the particular state of the json data.
body actual json data
created_at the time when the row was inserted in the table.
In this model, we can actually visualize that there is a unique index on row_key , column_name & ref_key. So every time we need some state of our domain, we have to query our store with these 3 columns.
Advantage of the approach is: it’s a very generic design. We don’t need multiple index any more. If the data store is sharded also, any query just need to go to a single shard as decided by the row_key & it will get the required data.
Disadvantage: Here we are using more memory as we might end up storing the same json data along with different required json attributes in the table.
Another approach to achieve the same schema less store is below.
We will have a table with same row_key , body , ref_key , created_at but we don’t have any column to store attributes of json. Rather, we create different dedicated table for required index. So consider our json is like following:
{'city': 'Bangalore', 'start_time': '2018-04-01 01:00:23', 'driver_id': 'jku6tr56', 'passenger_id': 'u12weoe'}
Now we want to have index on city + driver_id , passenger. So we create 2 tables. One with the columns — city , driver_id , entity_id & another table with columns — passenger_id , entity_id. Here entity_id actually points to the row_key of the actual domain model.
Advantage: For each index, we have a table, so crating a new index is easy, deleting an existing index is easy, just remove the index table altogether. No index cluttering.
Disadvantage: Searching might be a little pain though, search different index tables, aggregate them in the application code. Although, in both of the above approaches, application code has to handle a lot in terms of how data is parsed and manipulated in order to prepare the data for processing.
Over the top of such low level db models, a whole set of worker nodes can be created, storage nodes can be clustered. As the data store implementation is custom, you can implement event or trigger based systems so that when a new row is inserted, events get dispatched to other systems for further processing of data. Example: when trip data is written, trigger event to the billing system so that it can prepare the bill for the customer etc.
The whole aspect of discussing the above stuffs is that —it’s possible to build such a system on the top of MySQL. MySQL is not old school, it’s not always about fancy technologies, it’s the use cases and technical expertise that can help a company to identify the right solution, although in technology world, nothing is persistent, things are pretty dynamic. So it might happen that you really get a NoSQL solution which already does the same even in a better way. It’s upto the scale, criticality of data, tradeoffs & trust on the maturity of the system that decides if some has to be completely rewritten or not.
More information:
