How MVCC databases work internally

In my previous article, I discussed some internals on storage techniques of different sort of databases. LSM tree, fractal tree & B-Tree were discussed at a broader level so that we can get to know the overall designing behind such popular systems. It’s really a broad field to understand & discuss about database stuffs, there are so many complex things.
Today I am reflecting some light on another technique called Multi Version Concurrency Control which is used by very popular database systems like PostGreSQL, Couch DB, LMDB etc.
So from the name itself, it’s pretty clear that such systems maintain different versions of data with identifier like rev_no or version_no etc & when data is queried, the latest version is returned. It looks simple but there are many aspects to it.
Typically traditional database systems use locking when multiple readers & writes access some resource. It leads to a thread contention where multiple threads begs to CPU for certain resource. At a scale, this typical locking just performs poorly. MVCC exactly tries to solve this issue in a different way.
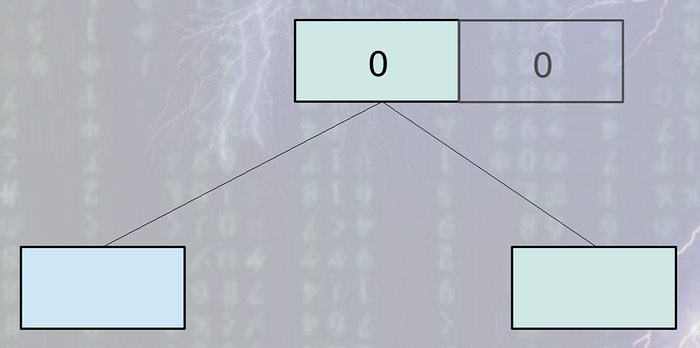
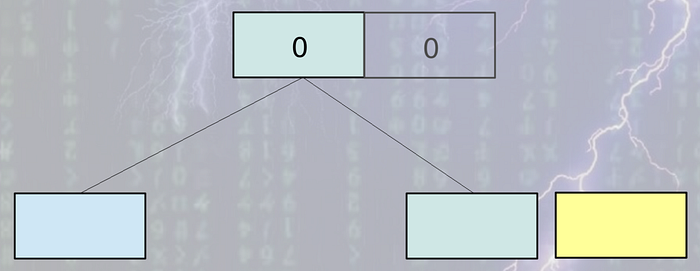
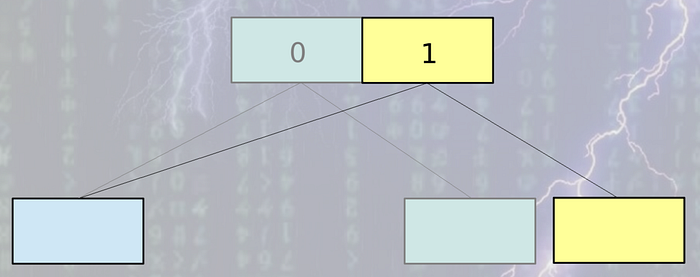
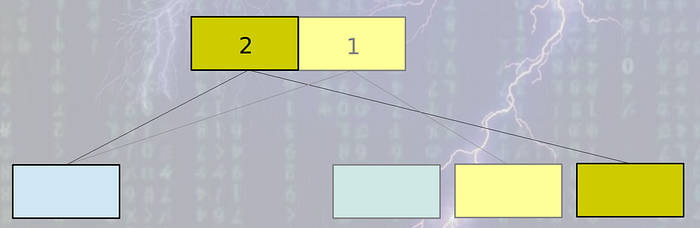
MVCC systems also use B-Tree internally. But it does not do in place B-Tree update as random write is very costly and less efficient in any kind of disk. Instead it takes append only approach like LSM tree systems. Each & every time some data is updated, a copy of the original leaf node is created and appended to the end of the file. Not only the leaf, but also the whole leaf to root path is recreated and appended to the end of file. Other nodes remain intact. The root node is always written last. So update operation is always bottom up.
The operations look like below:





So how do we find root in the above tree? As multiple roots might be there in the system, there should be some way so that we can find out the root. Typically databases like CouchDB or LMDB uses a special node called meta which is always there at the end of the file, it points to the root of the tree. So conceptually, root is not the last node written in the database file, it’s the meta page. So when file is read from the last, meta page can be retrieved, from meta page root is identified, from root the whole tree can be traversed.
So essentially append only or copy on write B-Tree is a random read and sequential write system. Random read is still better than random write :D.
From the above pictures, it’s clear that space tends to exhaust very fast with such arrangement especially in a high traffic environment. Still the IO performance is quite linear because write is sequential. As discussed in the previous article, if writes are batched and written in blocks, the write will be much much faster than randomly updating some page in the disk.
99% or more of the space usage will come from maintaining older data in the system if we continue doing operations like depicted above. So some mechanism has to be applied to reduce space overhead.
Following are some space management ways —
- Run compaction process or garbage collection in the background — maintain some metadata like reference counters for all nodes in the database file, periodically clean them up when reference count is 0.
- Get rid of perfect multi version concept. LMDB takes this approach. LMDB maintains 2 root pages mainly. Every operation reads both the pages from the end of the file. LMDB tries to manage operations between 2 roots only. But there is a problem with this approach. There might be some long running read operations which might point to a much older version of tree. In such cases maintaining 2 pages might not be effective if number of such older transactions is very high. So long running read operations have to be avoided. It happens like below:

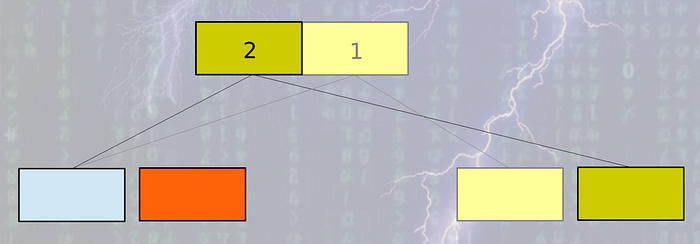
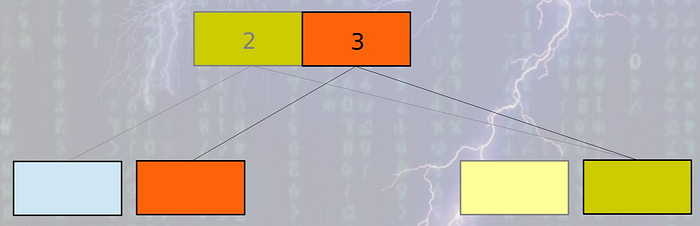
3. The third way is to manage list of free pages. The list might be managed on memory as well. So the intention is to use already freed pages as much as possible. In this way, the database can maintain a stable size. So you can consider it like a database with many used & unused pages. If you keep reusing the unused pages for new update operations, you might not need to do garbage collection at all. So no compaction / garbage collection, only need to manage list of free / unused nodes — a little bit of space overhead though but it’s worth it.
So append only or CoW B-Trees are very advantageous:
- Append only is very very fast on disk — magnetic hard drive or Solid State Drive whatever it is.
- Due to append-only nature, database is never corrupt, because what is already written to disk is immutable.
- Probably no need to maintain WAL — Write Ahead Log. Because database is never going to be corrupt. No in-place update, always the database has some consistent view.
- Backup or taking snapshot is easy. Normally for backup operation, you need to take the database offline or freeze it or stop doing update operations for some time because during backing up, if some update operation occurs, it might impact the backup or it might not be a part of the snapshot at all. Also there might be some problems with locking during backup etc. With append only, there is no such overhead as it’s the file already contains immutable state of data. Just copy the file to a different machine and done. Even if there is a downtime, it is very very small.
- There is ideally no locking involved. So writers don’t block readers, readers don’t block the writer. Readers always see some consistent view of the database. So you can ideally run single serialised writer with multiple readers.
- After crash, there is no rebuild or reindex required. Just backup of the database file is enough.
- Replication is also as simple as backup.
Some disadvantages:
- High space usage is the biggest issue. Everything in the world comes at a cost. So the speed of such systems comes from such space overhead.
- B-Tree is a very highly compact data structure i.e; the internal or branch nodes contain array of hundreds or thousands of keys. So it boils down to similar number of children per branch node. So there are thousands to millions of leaf to root path that might get practically copied at high scale.
So append only design is really a fantastic way of optimising write operations, although as other things, such system also have their own use cases where they may perform the best. It all depends of how much experiment you do on different aspects of a system before choosing it for your use case. This internals are just at the core of database systems. There are also many tricks, techniques & design decisions used to scale databases to meet modern day infrastructure needs. We will explore them soon.
Stay tuned.!
