Consistency Guarantees in Distributed Systems Explained Simply
Unrelated and Unusual Note: I am devastated seeing India’s helpless COVID-19 second wave situation due to severe Oxygen, medical equipment supply shortage and broken supply chain. I have been in a dilemma whether to publish any article at all since so many people are posting all around to seek help, the overall mood is a bit gloomy. However, it’s part of life and learning should never stop as long as we are healthy. So, here I am with the hope and prayer to see India coming out stronger.
Let’s pray for India together and continue our learning!
Introduction
When we discuss system design whether for a real or an imaginary system, most of us quite frequently use buzz words like strong consistency, eventual consistency etc. But do we really know what these terms exactly mean? What low level guarantees does strong consistency provide that eventual consistency does not provide? How do we reason about using such concepts in our design? There are lot of confusion in how different sources define consistency guarantees, language used is also very confusing, many articles even contradict with each other.
In this article, we’ll dive deep into the details of few important consistency guarantees in easy to understand words.
What and Why Consistency Guarantees
Imagine there is only a single thread accessing an object in your system. There is no interference from any other thread. How easy is it to define the correctness of the operations that happened on that object? Since operations are happening one by one by in a single thread, each operation completes only after the previous operation finishes. Hence, if we take inputs one by one, run the program to manipulate the object and manually verify the output, as long as the output is consistent as per the input provided, the operations are valid. But how would you define correctness in a multi threaded, multi processor environment where multiple threads / processes may access the same memory location together?
As developers, we need certain guarantees from the system regarding how different operations would be ordered, how updates would be visible and essentially what would be the impact on performance and correctness of the system in the presence of multiple threads of execution or processes. Consistency model defines that abstraction. It’s not a fancy new term in distributed systems, in fact, the concept already exists in the world of computer memory. Distributed systems like new age databases, cache, file system etc extend the same concept in their own way.
Distributed systems are all about choosing the right trade-offs, similarly, we’ll shortly see, consistency models are trade-offs between concurrency of operations vs ordering of operations or in other words, between performance and correctness of the operations.
The History
Historically, database systems and distributed systems are actually two different world. While distributed systems world concerns about highly concurrent machines interacting among each other (across geo locations), traditional databases research used to be more focused on non-distributed systems. But as the world became increasingly more online, massive amount of data started pouring into companies resulting in serious thoughts in distributed (cross geography) databases — NoSQL and then NewSQL etc. Essentially, a distributed database is a database built on the principle of distributed systems, hence it had to borrow the notion of consistency from the world of distributed systems.
Consistency is confusing, it’s an over loaded term in computing. It has different meaning in different contexts:
Consistency in Database Systems: Database consistency ensures the data base entities are in healthy state i.e; they follow all the application integrity constraints. Ex: any operation must make sure maximum data type length, unique key, primary key, foreign key constraints etc are absolutely maintained. It does not care about the operation operating on the given data, rather the relevance of the outcome of the operation is more important.
Consistency in Distributed Systems: Consistency in distributed systems means every node / replica has the same view of data at a given point in time irrespective of whichever client has updated the data. When you make a request to any node, you receive the exact same response (even if it’s an error) so that from the outside, it looks like there is a single node performing all the operations.
Note: In this article, we may use the terms distributed system, distributed database, data store or data storage interchangeably across different examples.
The Challenge with consistency in Distributed Systems
For serving massive online traffic in the modern internet, it’s very common to have an infrastructure set up with multiple replicas (or partitions). Whether it’s your Facebook activity, GMail data or Amazon’s order history — everything is replicated across datacenters, availability zones and possibly across countries to ensure data is not lost and the systems are always highly available in case one of the replica crashes. This poses a challenge — how to have consistent data across replicas? Without consistency, a mail that you have sent recently through GMail might disappear, an item deleted from Amazon cart might reappear. Or even worse, a financial transaction might be lost causing thousands of $$$ loss. While losing cart items is okay at times but losing $$$ is a big NO NO!
Hence different systems have different consistency requirements and systems should offer flexibility in how to configure consistency for different kind of operations.
Consistency Guarantees
Before we dive deep into discussing consistency guarantees, let’s look at few important definitions we are going to encounter frequently.
Program Order
A program is typically a sequence of instructions. When the program runs as a process, the instructions are run in the same order and this is called program order.
Unit of execution
An actor which operates on a memory location / object / variable is called an unit of execution in our article. A process in a computer system, a thread in a multi threaded environment or a client making a request (REST / GRpc call whatever) to an external (distributed or non-distributed) system is an unit of execution. Note that any such client request boils down to being a thread or process in the machine which processes the request since essentially a distributed system is nothing but a collection of machines capable of running multiple threads and processes concurrently or in parallel. We’ll use this term heavily in our article.
History
A sequence of operations executed ( possibly by multiple different units of execution) on an object / memory location is called history.
Perspective
There are majorly two different perspectives based on how the consistency guarantee synchronizes data:
Data-centric: The system is aware of multiple units of execution acting on given data and it synchronizes data access operations from all of them to guarantee correct result.
Client-centric: The system only cares about data access operations from the concerned process operating on the given data and it assumes that other unit of executions either don’t exist or don’t have any significant impact.
The following shows few important consistency guarantees which we’ll discuss in this article.

Broadly, there are two kinds of consistency: Weak Consistency and Strong Consistency.
Weak Consistency
I believe most of us are familiar with NoSQL data stores like MongoDB, Amazon Dynamo DB, Cassandra etc. If not, at least we have heard about it. These systems are usually known for built in high availability and performance. In the presence of partition and network issues, they embrace weakness in consistency to support such behaviour. As you can see in Figure 1, weaker consistency means higher availability, performance and throughput although more anomalous data.
Let’s look at few types of weak consistency guarantees below.
Eventual Consistency
Eventual consistency is the weakest and probably the most popular consistency level, thanks to the NoSQL movement and all content creators who have PhD in eventual consistency :P.
In a distributed system, replicas eventually converge to the same state. Given no write operation is in progress for a given data item, eventual consistency guarantees that all replicas start serving Read requests with the last updated value.
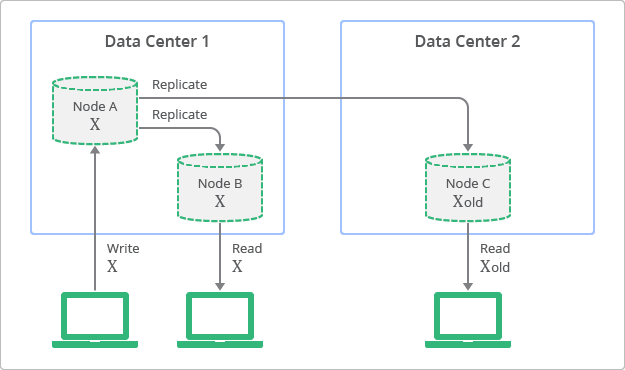
The above example uses a replication scenario to explain eventual consistency:
- All the replicas i.e;
Node BandNode Care highly available for reads. - A write on
Node AforXoriginates inData Center 1. SinceNode B
co-exists withNode Ain the same data center, the replication is fast there possibly apparently instantaneous. - However, it takes some time for cross data center replication i.e; from
Node AinData Center 1toNode CinData Center 2. - While the cross data center replication is going on, if any Read request occurs in
Node CforX, it returns oldXwhereas the same request could have received the latest value if it had landed onNode Bmeaning the overall system is eventually consistent.
Properties:
- There is absolutely no ordering guarantee on Reads and Writes. Arbitrary order applicable.
- Any unit of execution which writes some value to an object, upon reading the same object back from another replica, the update could be invisible.
- Reading the same data from different nodes simultaneously may return stale data.
Visualization:

Metrics:
- Data consistency: Lowest
- App availability: High to Highest
- Latency: Low
- Throughput: Highest
- Perspective: Client-centric
Real Life Examples:
- The best and well known example is Internet Domain Name System (DNS) that successfully caters to billions of requests daily. DNS is a hierarchical, highly available system and it takes some time to propagate the update for a given entry across DNS servers and clients.
- Review or ratings of products in Amazon.
- Count of likes in Facebook.
- Views on YouTube videos.
- Stream of comments on Facebook live videos.
- Ticket price shown on the front page in an airline website.
- Fetching how many Facebook friends / WhatsApp contacts are online.
Consistent Prefix Read
Consistent Prefix Read guarantees no replica reads data out of order even though the data read is stale at a given point in time. If a data x has gone through 3 versions say A, B, and C respectively with C being the most updated version, every replica receives these updates in the same order. At some point in time t, when you query a replica for x:
- It serves version
Aif it has replicated versionAonly till timet. Any future query won’t readxwith version less thanA. - It serves version
Bif it has replicated versionA,Bin order till timet. Any future query won’t readxwith version less thanB. - It serves version
Cif it has replicated versionA,B,Cin order till timet. Any future query won’t readxwith version less thanC. - and so on…
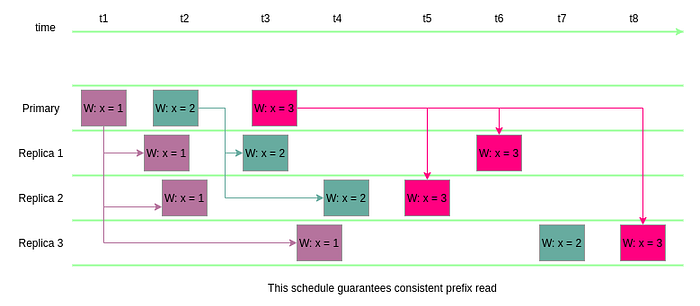
Here,
Replica 1,2, and3replicates different versions ofxin the order in which it’s written to thePrimarynode.- However, there could be huge gap between any two such replications. Example:
Replica 3receivesx = 1at timet3andx = 2at timet7 > t3. - At time
t5, if you query all these nodes forx, thePrimaryreturnsx = 3,Replica 1returnsx = 2,Replica 2returnsx = 3andReplica 3returnsx = 1. Hence different nodes return different versions of the same data at the same point in time, still they guarantee Consistent Prefix Read here.
Properties
- Dirty Read / Stale Read is possible.
- Global ordering guarantee applies for a given piece of data across replicas. Hence any unit of execution reads the operations in the same order.
- No bound on staleness. A replica can replicate the latest version of a data in
2 mswhereas another can do in100 msor200 msor any arbitrary time. This makes Consistent Prefix Read a weaker consistency guarantee. - At time
t1, if a replica serves versionAof a data, at timet2 > t1, it’ll either serve versionAor higher if a newer version of the data gets replicated but never any lesser one.
Visualization:

Metrics:
- Data consistency: Low
- App availability: High
- Latency: Low
- Throughput: Moderate
- Perspective: Data-centric
Real Life Examples:
- Sports apps which track score of soccer, cricket etc.
- Social media timelines (sorted by recency).
Session Guarantees
Session: It’s an abstract concept to correlate multiple Read and Write operations together as a group. Example: when you login to Amazon for shopping, a session is created internally which keeps track of your activities and browsing history, cart updates for that session. Sessions can be identified with a unique id called session id. The life time of a session could be few seconds to days or more depending on the business use case. When a group of Read / Write operations are to be performed, we can bind all these operations together within a session, the client can keep on passing the corresponding session id with all requests to help correlate them. We can provide a bunch of consistency guarantees on all the operations in a session. These guarantees ensure that the unit of execution does not at least see any anomaly in Read and Write operations during the active session. Across sessions, the guarantees may not apply. Hence, these guarantees come under weak consistency.
Session guarantees are particularly useful when strong consistency is required for the concerned unit of execution in a session but not globally.
Let’s look at four important session guarantees below:
Read-Your-Own-Write (RYOW) / Read-My-Write
In a distributed system, depending on the architecture, either any replica can accept Read or Write requests or a particular designated node (called leader) accepts writes and all other nodes (called followers) accept Read requests. In reality, there is always some replication lag especially for cross datacenter traffic and it causes the follower nodes or Read serving nodes to return stale data in response to Read requests even in the same session. This is a very common case in many modern NoSQL based systems. If this happens, we say, Read-Your-Own-Write / Read-My-Write consistency is violated.
Consider the following example.
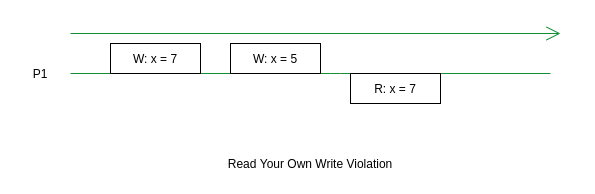
- An unit of execution
P1writesx = 7and some replicaR1handles the request. - Then it updates
xto5and another replicaR2handles the request. - Next time, when
P1readsx, it expects to see5, rather it observes the older value7probably because the replicaR1has handled the Read request and it has not yet seen the latest update handled byR2. - The same concept can be extended in computer memory system also by replacing replica with processors.
This is a clear violation of RYOW consistency since there is only a single unit of execution performing the Write and Read operations yet it’s unable to see its own update.
Q. How could we make the above example guarantee RYOW consistency?
A. There could be couple of ways:
- Make a single replica say
R1in our example handle all requests from the same unit of execution. This makes RYOW sticky in nature. In a leader-less distributed system, a specific node can be designated to serve all Read and Write requests for a particular data. A separate configuration store can maintain the mapping between the data and chosen server. - Or, if multiple replicas have to be used, ensure Write operation by any processor is synchronized to all other processors. In case of a leader-follower based distributed system, a Write on the leader succeeds only when it’s synchronously replicated to all the followers. Or, without using synchronous replication, replicas can be configured to load data lazily
(on-demand) from the leader if they don’t find the required result.
Properties
- If a Read
Rfollows a WriteWby the same unit of execution,Rshould seeW. - As long as all the requests in a session are served by a single processor / replica or a set of suitable processors / replicas (sticky requests) who know about all updates on the concerned variable / object, the unit of execution should be able to see all updates performed by itself.
- In case of a distributed system, sticky request also means — if a network partition occurs, the client must connect to the same server with whom it was talking to before the partition.
- Other units of execution may not see (no guarantee) the update done by the current unit of execution.
- Since RYOW is only about consistency in a session, it’s overall a weaker consistency guarantee.
Real Life Example
- If you delete a mail from Gmail and you get the confirmation, upon refreshing the page, you should not see the mail again in RYOW consistency.
Monotonic Read
Monotonic Read guarantees — if a Read R0 observes Write W for a piece of data, further Read R1 by the same unit of execution for the same data in the same session should at least observe W or more recent value.
In case of a distributes system having multiple replicas, the client can reach out to any replica as long as they have enough updates at least till W for the concerned data.
Let’s look at the following example:
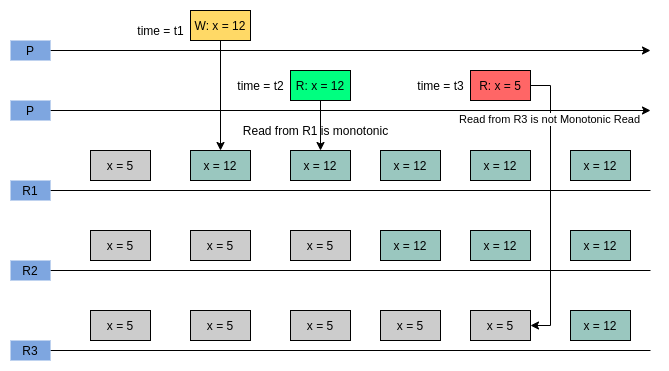
Here,
- Initially all the replicas contain the same
x = 5. - At time
t1, the clientPwritesx = 12and let’s assume it’s immediately replicated toR1. - As time
t2 > t1,Pmakes a Read request forxtoR1and asR1is already aware of the update, it returns the latest value12toP. This is Monotonic Read since from timet1,R1always returns either12or any later value. - At time
t3 > t2 > t1, replicaR3is still unaware of the update due to replication lag, hence it still holds the older valuex = 5. When the same processPrequestsR3for the latestx, it returns5which confusesPsincePhas already seen the latestx = 12in the earlier call. This Read is non-monotonic read.
Properties
- It’s not a global consistency guarantee, it’s local to a session, hence updates performed by the current unit of execution might be invisible to others.
- If we assume, with every write, the version of an object increases, each subsequent Read should see the same or monotonically increasing version of the object.
- Monotonic Read is also sticky in nature like RYOW. As long as the same processor / server or same set of designated processors / servers handle the requests for the same unit of execution in the same session, Monotonic Read should be guaranteed.
- After network partition, in a distributed database, the client should connect back to the same server / same set of servers.
Real Life Example
- You open Gmail. The mail client makes a request to fetch all the latest aggregated mails. Now you click on the top mail. The mail client makes another request to fetch the content of the mail. What if the second request lands on a server which is unaware of the latest update and fetches nothing? This is possible in a Non-Monotonic Read scenario. The second request should be routed to such a server which has seen the latest data that’s already reflecting in the first request.
Write Follows Read (WFR)
Let’s say there is a server S1 where Write W1 precedes Read R1 i.e; R1 has seen the effect of W1. R1 precedes another Write W2 and W2 depends on R1. In such a case, WFR provides 2 guarantees:
Ordering guarantee: W2 should follow all those Writes which caused R1 (all relevant Writes to R1). In our case, W1 is the only relevant Write for R1. Hence, the Write order should place W2 after W1 in S1. This guarantee applies within the session. Eventually, all other replicas should see the same order of Write operations, hence this order essentially acts as a global order.
Write propagation guarantee: If R1 occurs in server S1 at time t1, then for any server S2, if S2 has seen W2 at time t2 > t1, S2 must have seen all relevant Writes to R1 i.e; in our example, W1 prior to W2. It means all other replicas in the system should apply a Write after they have seen all the previous Writes on which it depends. This guarantee applies outside of session. Note: propagating the changes may take some time depending on implementation, WFR does not require any real time or instantaneous propagation of changes.
Consider the following example:

- For simplicity purpose, let’s say the replica
R1is serving all Read and Write requests.xis already set to5by some earlier Write. At timet1, session 1 readsx = 5and writesy = 10toR1at timet2. Session 1 is aware of the latest state ofxandy. - Time
t2on-wards, replicaR1servesx = 5andy = 10to all requests. And as per the definition, this behaviour maps to ordering guarantee of WFR sincey = 10takes place att2after observingx = 5att1. R1instantaneously replicatesy = 10at timet2to replicaR2.- When session
2makes a Read request toR2at timet3, it observes olderx = 0but latesty = 10which does not follow the propagation guarantee in WFR. Hence it does not maintain WFR consistency. - Due to some issue or replication lag,
R1replicatesx = 5toR2at timet5. - From
t5on-wards,R2also has latestx = 5andy = 10. Hence any Read request served byR2observes both the latest values and it appears as if these requests obey WFR consistency.
Properties
- Ordering first applies within the involved session.
- Outside of the client’s session, propagation of writes in order of their occurrence should be done to guarantee WFR. Note that, eventually, changes outside of session will be visible to all other units of execution as well due to the propagation guarantee.
- The propagation can be lazy or non-real time thus making the guarantee weak.
- This consistency is also called session causality.
Real Life Example
- Consider replying to a tweet. You can only do that when the tweet is already written to the system and is visible to you. Both reading and replying could be done in the same session.
Monotonic Write (MW)
A write operation by a process on a data item
xis completed before any successive write operation onxby the same process.
Similar to Write-Follows-Read, Monotonic Write can also be broken into two different guarantees:
- Ordering Guarantee: An unit of execution should see its own successive updates on a particular variable / object in the order of their occurrence. This guarantee applies within the session.
- Propagation Guarantee: Eventually, all other replicas should see the writes on the object in the same order. This applies outside of the session.
Consider the example below:
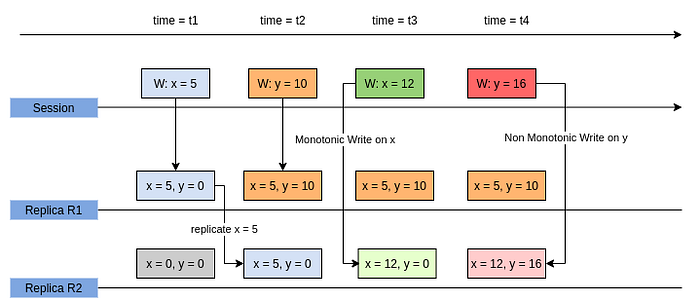
- At time
t1,x = 5is updated in replicaR1and at timet2, this update is replicated to replicaR2. - At time
t2itself,y = 10is updated inR1however it never gets replicated for some reason. - At time
t3 > t2, the client session updatesx = 12inR2. SinceR2is now aware of the latest update onxdue to earlier replication, this current update operation onxobeys MW consistency. - Similarly, at time
t4, the client session updatesy = 16inR2. Since the latesty = 10inR1is not replicated toR2yet, current update operation inR2operates on oldery = 0. Hence this operation does not obey MW consistency.
Properties
- It’s a weak consistency guarantee given the guarantee concerns about an unit of execution within a session only.
- If a Write
W1happens before another WriteW2in a session, still the unit of execution is unable to seeW1while executingW2, the session is said to be out of order. - While an unit of execution is under MW guarantee within a session, other units of execution might not see the same updates on the same object at that point in time. MW does not give any guarantee on propagation time.
- Similarly, operations on the same object by other units of executions are not also guaranteed to show up during the current unit’s session.
Real Life Example
- Consider editing an Wikipedia article. The system should guarantee that version
n + 1always replaces versionnfor updates performed by the same client, not the other way around. For other clients, these group of updates could be propagated at a later point in time in order. This can be guaranteed by Monotonic Write within a session.
Session Consistency Visualization:

Session Consistency Metrics:
- Data consistency: Moderate
- App availability: High
- Latency: Moderate
- Throughput: Moderate
- Perspective: Client-centric
Session Consistency Real Life Examples:
- Shopping cart. If you add some item to cart in amazon.in, those items won’t be visible in amazon.co.uk as that’s another session.
- Updating profile picture on social media like Facebook, Twitter. You can see your own updates but there is no guarantee others see it during initial few seconds at least.
Causal Consistency
Causal consistency enforces ordering of only related writes across units of executions.
What does related Write mean?
Say, if an unit of execution reads a variable x and depending on its value, updates another variable y, we say, Write of y happens after (causally dependent on) Read of x. Causal consistency guarantees that all units of execution observes new value of y only after observing the related value of x (dependency).
Let’s consider the following examples:
Example 1

Here,
P1writesx = 5to the system.P2readsx = 5and then writesy = 10, let’s assume that there is some program logic which determines the value ofybased on the value ofx. This makes the Write ofybyP2causally dependent on the earlier Write ofxbyP1i.e; they are related. After the successful Write ofybyP2, if any unit of execution wants to read bothxandy, causal consistency expects them to observexfirst thenyeven with stale value. Here an important thing is: in which order the variables are observed is more important than the actual value observed while reading.
Q. What if an unit of execution, P5 only readsxory, not both?
A. That also qualifies for causal consistency since only a single value is read.P3observes the latestx = 5first, then an oldery = 0, then the latesty = 10. Fetching olderyeven though it’s already updated in the system creates an impression that update onxhappened before update ofy. Sinceyis causally dependent onx, this observation is completely fine andP3’s operations are causally consistent.P4first seesy = 10and then olderx = 0instead of the latestx = 5. It gives an impression toP4thatyis written to the system beforexwhich is actually incorrect. Hence it violates causal consistency guarantee. IfP4would have observedx = 0beforey = 10, it would have been causally consistent too,x = 0is allowed instead ofx = 5since it might happen the processor / node executingP4has not yet seen the other processor / node writingx = 5which has executedP2.
Example 2
The following example is causally consistent:

Here, unlike the previous example, P2 does not read x first, it simply writes y = 10 without depending on x. Essentially y is not causally related to x. Hence other units of execution can read x and y in any order and all such cases are causally consistent.
Example 3
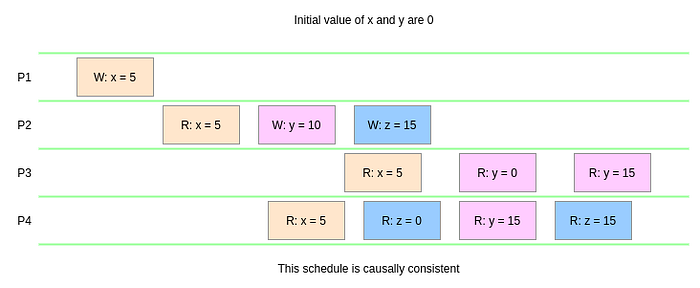
P2readsx = 5and writesy = 10,z = 15depending on that. Bothyandzare causally related (dependent) onx.P3reads the latestx = 5, then oldery = 0, then the latesty = 15. Observing the update sequence ofy,P3knowsyhappened beforexand this is true indeed.- Similarly,
P4reads the latestx = 5, then olderz = 0, then the latesty = 15interferes, thenz = 15. Hence thex, the cause ofzis visible toP4in the expected order:xhappened beforez. Note that the interference ofy = 15does not make any difference since it’s the latest value only.P4has no way to identify whetherxhappened beforeyoryhappened beforex. Hence, the sequence is causally consistent. - Note that the sequence of operations observed by different processes / servers don’t need to be same to qualify for causal consistency.
P3andP4observe two different sequence, yet they are causally consistent.
Properties
- Only related writes are ordered in the order of their occurrence across units of execution. Unrelated writes can be placed in any order. Hence, there is no notion of global ordering in a causally consistent system.
- No real time constraints imposed.
- As mentioned, order in which variables are observed is more important than the real value observed at the time of operation.
- Different units of operation might observe different causally consistent sequences at the same time.
- Causal order is transitive:
Ahappens beforeB,Bhappens beforeCmeansAhappens beforeC.
Metrics:
- Data consistency: Moderate
- App availability: High
- Latency: Moderate
- Throughput: Moderate
- Perspective: Data-centric
Real Life Examples:
- You post an important status on Facebook asking for some help. After sometime, you realize there is some mistake in the information provided, you go ahead and update the status. Now your online friends should get the update as soon as possible. They can receive the update at different time depending on how their feeds are formed. If eventual consistency is used, some of your friends may still see the older status with wrong info even after long time. But since the event of updating the status causes feed change of online friends, it can be considered as causal consistency.
Bounded Staleness Consistency
Bounded staleness is very near to strong consistency and an extension to consistent prefix reads guarantee but with the flexibility to configure the staleness threshold of the data. Basically users can define how much stale is stale for their use case.
User can configure the staleness threshold in couple of ways:
- Time: The Reads on a data item can be configured to be stale (lag behind the Writes) by maximum specified time. Example: If the configured stateless time is
5seconds and current time ist = 11:00 AM, updates on the item done before(t — x) = 10:55 AMare to be considered stale. Updates performed within the last5seconds window is allowed. - No of versions / update operations: For a given item, the reads might lag behind writes by maximum
kupdates or versions. - Out of these two conditions, whatever is smaller / reached earlier gets applicable.
Properties:
- Like Consistent Prefix Read, global ordering guarantee is there but coupled with configurable threshold as mentioned. So, Reads are consistent beyond the threshold.
- If you identify the threshold suitable for your use case, the performance could be better than strong consistency.
- Far more expensive than session, consistent prefix, eventual consistency etc.
Visualization:
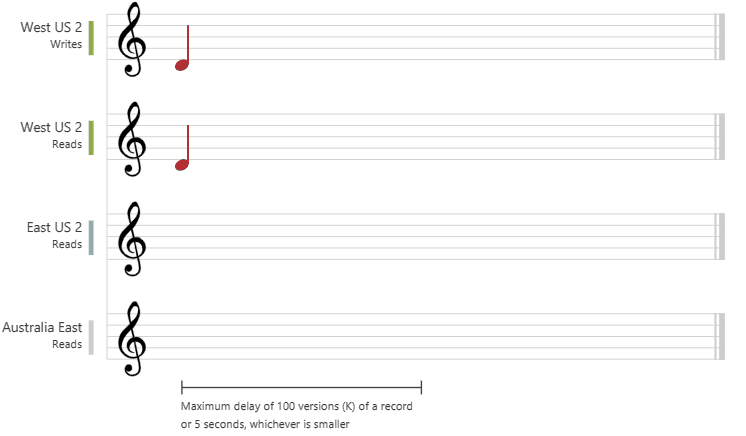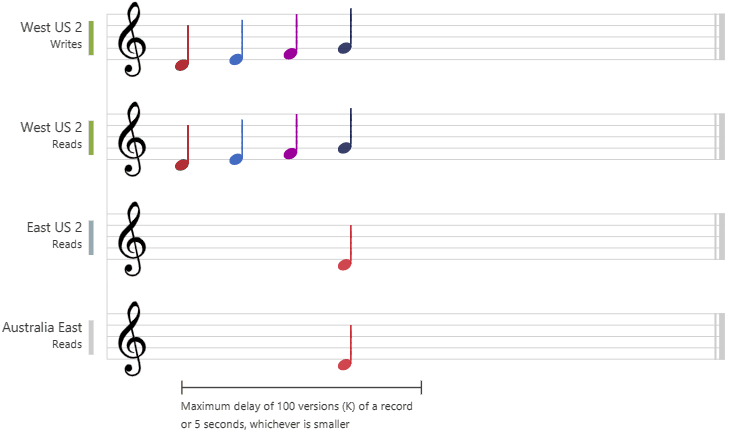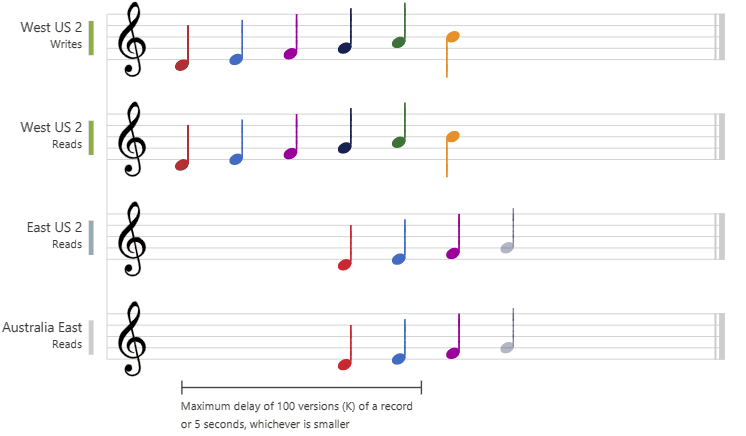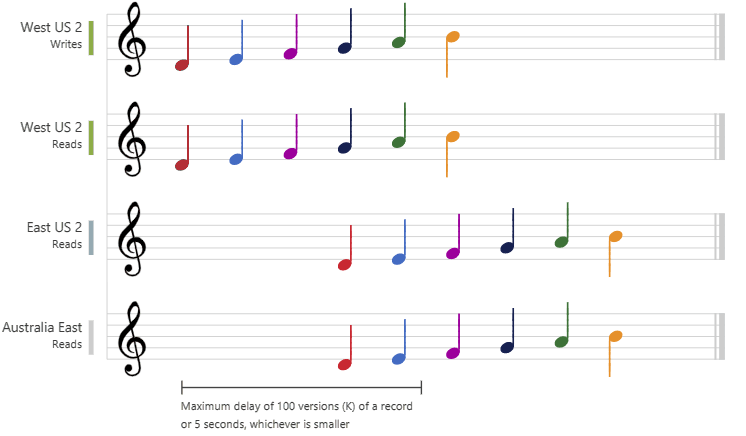
Metrics:
- Data consistency: High
- App availability: Low
- Latency: High
- Throughput: Low
- Perspective: Data-centric
Real Life Example:
- Stock ticker applications.
- Weather tracking apps.
- Mostly, any status tracking apps should be bounded in staleness.
- May be, online gaming apps.
Strong Consistency
Conceptually, strong consistency is exact opposite to eventual consistency where all the replicas read the same value for a given data item at the same point in time. Certainly, ensuring strong consistency across data center even across multiple nodes in a single data center is expensive.
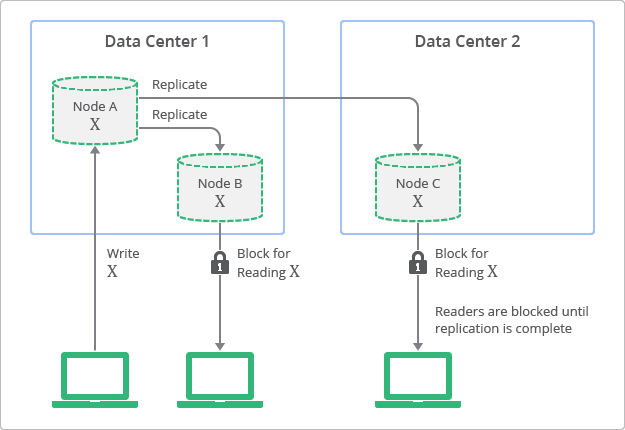
The above figure shows how we intuitively think of strong consistency in our mind when we talk about it. This is just a conceptual illustration, not necessarily a real life implementation.
- When
Node Areceives an update for itemX, it locks the item across replicas immediately to propagate the update at once. - While the item is locked, Read operation is blocked on it at all replicas to prevent inconsistent or dirty reads.
- Locks are released once the item is updated across replicas.
Let’s look into different variant of Strong Consistency below:
Sequential Consistency
In a single threaded environment, a thread can invoke an object multiple times, but the current invocation happens if and only if the previous invocation completes. Hence, in such a scenario, we have a chain of Invocation (I), Response (R) messages and note carefully, each invocation I is followed by the corresponding response R. This is a sequential history and it’s easy to explain that the operations are sequentially consistent since no other thread interferes the executing thread.
I = Invocation, R = ResponseSequential History : I1 R1 I2 R2 I3 R3 ... In Rn
Q. How do we extend the concept to multi threaded environment? How do we order operations in such a case?
A. Sequential consistency ensures that each thread individually executes operations in the program order. In the following example, thread A always invokes A1 operation, gets response, then execute A2 operation and gets response, hence operations order is: IA1 -> RA1 -> IA2 -> RA2.
Similarly, thread B executes operations in IB1 -> RB1 -> IB2 -> RB2 order.
I = Invocation, R = Responsethread A: IA1----------RA1 IA2-----------RA2
thread B: | IB1---|---RB1 IB2----|----RB2 |
| | | | | | | |
| | | | | | | |
real-time order: IA1 IB1 RA1 RB1 IB2 IA2 RB2 RA2
-------------------------------------------> time
But there is no ordering guarantee among multiple threads, there could be interleaved operations across threads but threads individually obey program order. Hence, any of the following history is legal and valid in sequential consistency:
1. IA1 RA1 IB1 RB1 IB2 RB2 IA2 RA2
2. IB1 RB1 IA1 RA1 IB2 RB2 IA2 RA2
3. IB1 RB1 IA1 RA1 IA2 RA2 IB2 RB2
4. IA1 RA1 IB1 RB1 IA2 RA2 IB2 RB2
5. IA1 RA1 IA2 RA2 IB1 RB1 IB2 RB2
6. IB1 RB1 IB2 RB2 IA1 RA1 IA2 RA2The above example is purely from Write perspective. What about Read operations?
Consider the following examples:
Example 1

Here,
P1writesx = 5,P2writesy = 10. They don’t see each other’s update. Hence these two operations are sequentially consistent.P3reads the latestx = 5, then oldery = 0, then newery = 10. Since,P3has observed the update sequence ofyafter fetchingx, it gets an impression thatxis written to the system beforey.- Now
P4straight forward observes the latesty = 10andx = 5. Note that these are independent Read operations byP4. No update sequence for any of the variables has been observed byP4. HenceP4has no way to identify ifxis written beforeyor vice versa. Any sequence is fine for it.
Note: The update sequence is the key differentiation here. - Thus both
P3andP4agrees to the same sequence:xis written beforeyin the system. Hence the system has sequential consistency guarantee. - If both threads would have observed only the latest value of
xandyin any order, they would have no way to identify whetherxis written beforeyor vice versa. Hence that sequence would be sequentially consistent too.
Example 2

P3again observes the update sequence ofyfrom0to10after fetchingx. HenceP3thinksxis written beforeyin the system.- However,
P4this time observes olderx = 0after fetching latesty = 10.P4thinksyis written beforexin the system. IfP4fetchesxagain, it could possibly observe the latestx = 5.
Note: Again the possible update sequence is the key differentiation here. - Thus
P3andP4observes completely opposite sequence of operation and they are not sequentially consistent.
What are the observations from both these examples?
The update sequence. If any thread observes an older value of a variable, later observes a newer value for the same variable, that sequence defines order of operations on the variable with respect to the other variables in the system for that particular thread. For the same set of variables, as long as all the units of execution observe the sequence of operations in the same order, the operations are sequentially consistent.
Note: Sequential consistency does not enforce Read operations to happen exactly in the order of Write operations for a given set of variables. Read could be performed in any order as long as same or equivalent update sequence of concerned variables is observed by all units of execution. Essentially, it’s all client view that matters.
Consider the following example to understand it better:
Example 3

P3reads the latesty = 10, then reads the olderx = 0. ButP3does not know yet thatx = 0is actually a stale one. HenceP3does not identify whetherxis inserted beforeyin the system or vice versa. Any ordering is okay.P4observes the latesty = 10then the latestx = 5. Both are latest values meaningP4would not know whetherxis inserted beforeyin the system or vice versa. Hence,P4is fine with any order.- Actually, in reality,
P1writesx = 5beforeP2writesy = 10. Since both the threadsP3andP4do not know which operation has occurred before whom , they can assumeyis inserted beforex. Thus they both agree on the same view meaning the Read operations are sequentially consistent.
Properties
- Guarantees some valid, legal serial order of execution of Write operations.
- Guaranteed Write operation execution in program order for individual unit of execution.
- Has the freedom to shuffle Write operations (
(I, R)pairs) across different unit of execution for efficiency purpose. - While reading, only the update sequence of variables observed matters. The Read order could be different than actual Write order as long as the same update sequence is seen across all units of execution regardless of the actual value observed for any particular variable.
- If any unit of execution observes the latest value for a set of variables without observing any earlier value, it can’t really identify which variable is written before whom. Hence, any update sequence is for those variables is fine for it. Look at
P4in Example 1.
Linearizability
Linearizability is an extension to sequential consistency guarantee but stricter and often referred to as strong consistency. Any sequential history can be treated as a linearizable history if operation across units of execution maintain real time order i.e; writes (including unrelated writes) made by different units of execution are ordered in accordance with real time and they tend to be instantaneous (a valid response follows each request).
Consider the same example as in sequential consistency:
I = Invocation, R = Responsethread A: IA1----------RA1 IA2-----------RA2
thread B: | IB1---|---RB1 IB2----|----RB2 |
| | | | | | | |
| | | | | | | |
real-time order: IA1 IB1 RA1 RB1 IB2 IA2 RB2 RA2
-------------------------------------------> time
Here, the following histories are linearizable:
1. IA1 RA1 IB1 RB1 IB2 RB2 IA2 RA2
2. IB1 RB1 IA1 RA1 IB2 RB2 IA2 RA2
3. IB1 RB1 IA1 RA1 IA2 RA2 IB2 RB2
4. IA1 RA1 IB1 RB1 IA2 RA2 IB2 RB2 Note that (IA1, RA1), (IB1, RB1) overlap meaning we actually don’t know their exact real time order. Linearizability acknowledges such overlaps: there is always a gap between making a request and getting response for that request — especially in distributed systems where probably the Write is replicated across geography during this time period. Hence linearizability allows such operations in any order i.e; (IA1, RA1) can be ordered before (IB1, RB1) and vice versa. Similar logic applies for (IA2, RA2), (IB2, RB2). The group of operations [(IA1, RA1), (IB1, RB1)] fully precedes the group [(IA2, RA2), (IB2, RB2)]in terms of real time ordering. Hence any history where (IA2, RA2) or (IB2, RB2) comes before (IA1, RA1) or (IB1, RB1) is not linearizable by definition. The following history is not a valid linearizable history:
5. IA1 RA1 IA2 RA2 IB1 RB1 IB2 RB2So, in short, if there is a variable V, a Write operation W(V = 3) happens at time t2, if you fetch the variable’s value at time t3 where t3 > t2, you must see the latest value of the variable i.e; V = 3 irrespective of whichever unit of execution actually has written the value.
...W(V = 2)..W(V = 3) ....... R(returns 3 not 2)
------t1--------t2-----------------t3-----> timeCondition: t1 < t2 < t3
The above talks about Write operations only. What are the constraints for Read operation to guarantee linearizability?
The Read operations must also follow real time order i.e; any unit of execution must see the most recent value of a variable in real time irrespective of whichever unit of execution has initiated the Write request for the concerned variable. But yes, if a Read operation by an unit of execution T1 for a variable x overlaps with a Write operation on the same variable x by another unit of execution T2, real time constraint could be discounted and older value of the variable could be fetched.
Consider the examples below:
Example 1
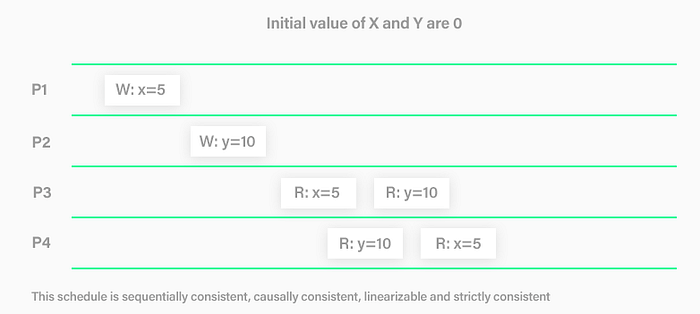
- As usual
P1andP2independently execute single operation on different variablesxandyrespectively, so they are linearizable. P3reads the most recentx = 5andy = 10in two independent operations. Note thatP3starts reading after bothP1andP2finishes. Hence observing the latest value forxandymaintains linearizability consistency.- Similarly,
P4reads the latesty = 10andx = 5in two independent operations.P4starts slightly afterP3meaningP4starts afterP1andP2finishes. Hence it observes the latestxandy. - Since none of
P3orP4observes any older value, by definition, this is a happy case of linearizability.
Example 2

- While
P1’s Write operation onxis going on,P3initiates a Read operation onx.P3fetches olderx = 0. Since these operations are overlapping, no real time constraint on ordering is imposed and hence these operations are linearizable. P4initiates reading ofyandxlong after they have been written to byP2andP1respectively. HenceP4gets the most recent values and it’s linearizable consistency.
Properties
- All units of execution obey program order and Write operations (including unrelated writes) are ordered by real time.
- Overlapped Write operations could be ordered in any way.
- Read operations must maintain real time constraint too. Only in case, a Read overlaps with a Write for the same variable, Read can return stale value.
- In a distributed system, if operation on each object is linearizable, then all operations in the system are linearizable.
Strict Consistency
Like linearizability, strict consistency is an extension to sequential consistency too but it is strictly coupled with real time ordering. We saw above that linearizability takes overlapped operations in a relaxed way, but strict consistency does not give that freedom. Overlapped operations also need to be ordered in strict real time order. This is the only difference between strict consistency and linearizability.
Let’s consider the following examples:
Example 1

Here,
P1writes:x = 5,P3readsxat the same time, both operations overlap butP3’s Read operation finishes a little while afterP1’s Write operation completes. Strict consistency guarantee expectsP3to seeP1’s Write i.e;x = 5whereas for linearizability, readingx = 0is okay since they overlap. Hence, the above sequence of operation is linearizable but not strictly consistent.
Example 2
P3andP4both initiates their Read operations afterP1andP2completes in terms of real time ordering.P3reads the latestx = 5first then the latesty = 10.- Similarly,
P4also observes the latest values ofyandxrespectively. Hence all these operations are strictly consistent.
Example 3
- Here,
P3starts after bothP1andP2finishes completely. Strict consistency requires any unit of execution to see the latest values if they are interested in reading the variables. P3observes the latestx = 5,then an oldery = 0. This older value violates strict consistency since they system already has an updated value ofywritten byP2a while ago.- Similarly,
P4also observes olderx = 0way long afterP1wrotex = 5. Hence it’s also a violation of strict consistency.
Properties
- Stricter than Linearizability.
- Maintains strict real time ordering for all Write operation including overlapped Write operations performed by any client / thread.
- Read operations across clients also observe the most recent value of variables in real time order.
- Strong real time adherence makes it the strongest level of consistency guarantee and practically impossible to implement in real life distributed systems.
Strong Consistency Visualization:

Strong Consistency Metrics:
- Data consistency: Highest
- App availability: Lowest
- Latency: High / Very High
- Throughput: Lowest
- Perspective: Data-centric
Strong Consistency Real Life Examples:
- Financial systems executing order payments flow or billing process.
- E-Commerce Flash sale apps (inventory related apps).
- Ticket booking flow while confirming the ticket.
- Meeting scheduling kind of apps.
Consistency in Real Life
We are now aware of the trade-offs offered by different consistency models. Building real life data systems like data storage systems is hard and they have to address varying use cases originating from different customers and no one Read or Write consistency guarantee can fit all the scenarios. Hence they usually offer different APIs for different use cases. Generally, in a distributed storage, operations concerning small set of entities like get(), set() etc can be strongly consistent. But again, there is no hard and fast rule regarding which APIs or what kind of entities (record, collection, whole storage) come under which bucket.
However, there are couple of factors to consider while choosing a consistency model in real life:
- How easy is the model to understand and develop for developers.
- Can your system handle weak / eventual consistency to certain level?
- Does adopting a different consistency level add significant storage and network cost?
- Does changing the consistency model affect the system performance? What is the measure?
Check out the following if interested to know how different popular data storage solutions offer their consistency guarantees:
Strong Consistency in Amazon S3
As a real life implementation of strong consistency, let’s look at how Amazon S3, the most popular object (most popular for files) storage system has recently incorporated strong consistency. There is not much details available, however, I will keep it short. More details can be found here.
S3 was originally developed as an eventually consistent, reliable, highly available and high performing object storage system. But over the years, customers started using it in different use cases which require strong consistency guarantee. Hence in December 2020, S3 rolled out strong consistency without any visible impact on original guarantees. At least this is what Amazon and its current CTO Werner Vogels claim.
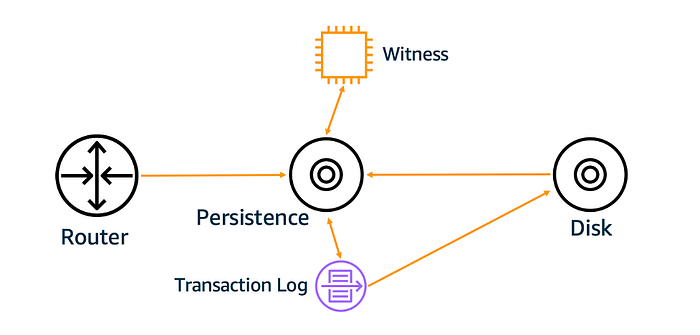
Let’s look into few important components:
Persistence: It’s the per-object metadata caching layer.
- If an object is written, deleted or moved to another bucket, the information is tracked here.
- Highly resilient.
- The system consists of many nodes.
- Eventually consistent. Hence, in the presence of network partition, Write and Read requests for the same object can be served by partitioned nodes with different view of the object.
Disk: Nodes actually storing the objects on disk.
The inconsistency issues actually came from the metadata cache layer described above due to its inherent eventual consistency support.
In order to make S3 strongly consistent yet ensuring the same level of performance and availability, Amazon implemented strongly consistent metadata cache layer by the following techniques:
- CPU cache coherence: CPU Cache Coherence is implemented to make sure the CPU cores in a cache node are synchronized and don’t see stale data since S3 is highly concurrent. Over the top, replication logic is implemented which replicates object updates in-order from one node to another and publishes these updates through internal notification mechanism.
- Witness: Just in case a cache node has stale data, how to identify that? Witness helps here to keep the cache consistent with the storage layer. It’s a highly available sub-system that is notified of every change per-object and maintains a little bit of state. Every time a Read is performed from the metadata cache, instead of checking with the storage layer, the cache actually checks with witness if it has the latest data for the object. In case the data is stale, the cache is updated with the latest data from disk storage before serving to the client request. Witness nodes store all data in memory, hence it supports high throughput and easy to scale up when a node dies.
This is how S3 overall achieved strong consistency without losing availability and performance guarantees.
Conclusion
If you have come this far, congratulations!!! You have conquered a tough topic in distributed systems. It’s funny to think that when we talk about strong consistency, we most probably don’t even know whether we are referring to linearizability or a little less stricter bounded staleness. As a distributed system architect, it’s very important to know which use cases would require what kind of consistency guarantees, otherwise incorrect trade-offs would become costly in near future.
It’s difficult to write articles on such topic. However, I hope all the examples, explanation and real life examples mentioned here per consistency guarantee make sense to you and help you understand them without much complexity.
Please provide multiple claps if you have liked the article and share on social media to make it reach bigger audience.
Feedback is appreciated.
Reference
- https://fauna.com/blog/demystifying-database-systems-introduction-to-consistency-levels
- https://www.cs.cornell.edu/courses/cs734/2000FA/cached%20papers/SessionGuaranteesPDIS_1.html
- https://stackoverflow.com/questions/9762101/what-is-linearizability
- http://csis.pace.edu/~marchese/CS865/Lectures/Chap7/Chapter7fin.htm
- https://dba.stackexchange.com/questions/279413/consistent-prefix-reads
- https://blog.jeremylikness.com/blog/2018-03-23_getting-behind-the-9ball-cosmosdb-consistency-levels/
- https://lennilobel.wordpress.com/2019/02/17/understanding-consistency-levels-in-azure-cosmos-db/
- https://cloud.google.com/datastore/docs/articles/balancing-strong-and-eventual-consistency-with-google-cloud-datastore
- https://jisajournal.springeropen.com/articles/10.1186/s13174-020-0122-y
